Linux内核(IO篇)
前言
目前笔者还在看其他人的博客了解基础流程的阶段,并没有根据源码进行分析。不过了解完之后笔者很快就会对源码进行分析了。
操作系统I/O基础
在计算机操作系统中,I/O就是输入(Input)和输出(Output),也可以理解为读(Read)和写(Write),针对不同的对象,I/O模式可以划分为磁盘IO模型和网络IO模型。
- 读操作:操作系统会先从内核缓冲区中查找是否有用户态所需要的数据,如果有就直接从内核缓冲区copy到用户缓冲区,供用户的应用程序使用。如果没有,对于磁盘I/O来说直接从磁盘中读取到内核缓冲区。而对于网络I/O,应用程序需要等待客户端发送数据,如果客户端还没有发送数据,对应的应用程序将会被阻塞,直到客户端发送了数据,该应用程序才会被唤醒,从Socket协议找中读取客户端发送的数据到内核空间,然后把内核空间的数据copy到用户空间,供应用程序使用。
- 写操作:用户的应用程序将数据从用户空间copy到内核空间的缓冲区中(如果用户空间没有相应的数据,则需要从磁盘—>内核缓冲区—>用户缓冲区依次读取),这时对用户程序来说写操作就已经完成,至于什么时候再写到磁盘或通过网络发送出去,由操作系统决定。除非应用程序显示地调用了sync 命令,立即把数据写入磁盘,或执行flush()方法,通过网络把数据发送出去。
设备硬件和内存之间的数据传输
PIO
PIO模式(Programming Input/Output Model)是一种通过CPU执行指令进行数据读写的数据交换模式,属于早期计算机系统使用的数据传输技术。其工作原理为CPU直接参与数据传输全过程,通过中断请求触发中断服务程序完成外设通信。
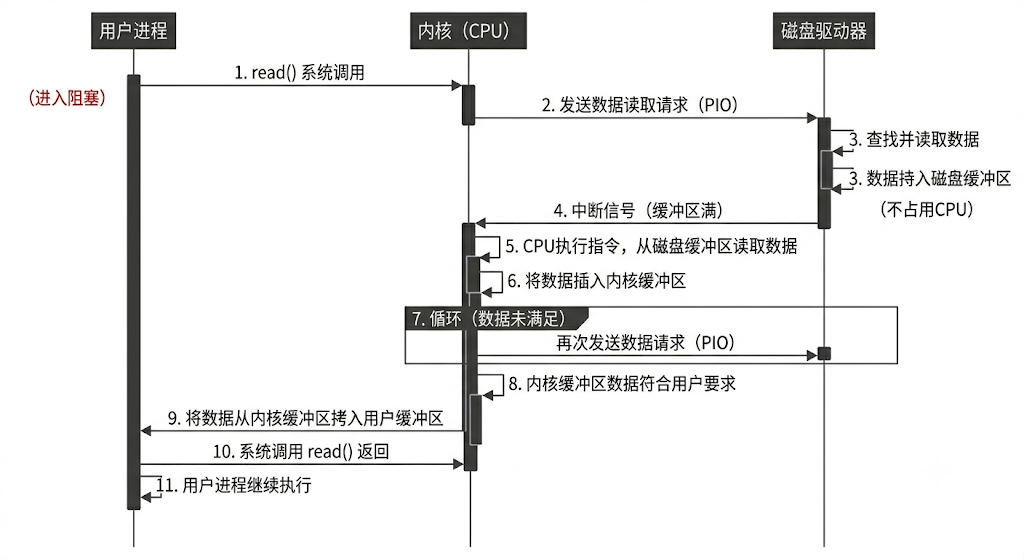
- 用户进程通过read等系统调用向操作系统(即cpu)发送请求,请求读取数据到自己的用户内存缓冲区中,陷入阻塞状态。操作系统获取请求后会将该请求递送给磁盘。
- 磁盘驱动器收到请求后查找数据,将数据拷贝到磁盘缓冲区中,此时不占用cpu。当磁盘的缓冲区被读满之后,向内核发起中断信号告知自己缓冲区已满。
- 内核收到磁盘的中断信号后,从磁盘缓冲区copy数据到内核缓冲区中。
- 如果内核缓冲区的数据没有满足用户所需要的长度,那么内核会再次向磁盘发送请求,直到内核缓冲区的数据符合用户要求的为止
- 内核缓冲区符合用户要求,cpu停止向磁盘IO请求,并将数据从内核缓冲区拷贝到用户缓冲区,同时会从系统调用中返回
- 用户读取到缓冲区的数据后继续执行原来的任务
DMA
直接内存访问(Direct memory accesses),该模式可以让I/O设备与计算机内存进行直接数据交换。而CPU则可以去忙别的事情。而磁盘和内核缓冲区之间的数据读写过程,需要使用cpu来协助的部分会单独拎出来做成一个独立部件,也就是DMA控制器。那么使用DMA的IO交互过程就变成了:
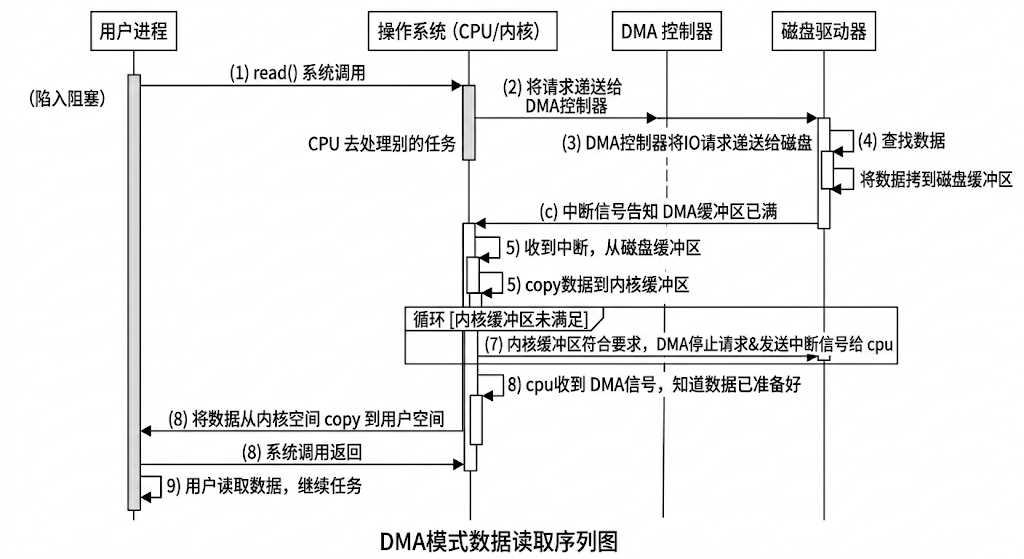
- 用户进程通过read等系统调用向操作系统(即cpu)发送请求,请求读取数据到自己的用户内存缓冲区中,陷入阻塞状态。
- 操作系统获取请求后会将该请求递送给DMA控制器。随后cpu就可以去处理别的任务了
- DMA将IO请求递送给磁盘
- 磁盘驱动器收到请求后查找数据,将数据拷贝到磁盘缓冲区中。当磁盘的缓冲区被读满之后,向DMA发起中断信号告知自己缓冲区已满。
- DMA收到磁盘的中断信号后,从磁盘缓冲区copy数据到内核缓冲区中。
- 如果内核缓冲区的数据没有满足用户所需要的长度,那么会重复3、4、5直到内核缓冲区的数据要求符合用户的要求为止
- 内核缓冲区符合用户要求,DMA停止向磁盘发送请求,并且发送中断信号给cpu
- cpu收到DMA信号,知道数据已经准备好,于是将数据从内核空间copy到用户空间,系统调用返回
- 用户读取到缓冲区的数据后继续执行原来的任务
跟PIO模式相比,DMA就是CPU的一个代理,它负责了一部分的拷贝工作,从而减轻了CPU的负担。
需要注意的是,DMA承担的工作是从磁盘的缓冲区到内核缓冲区或网卡设备到内核的 soket buffer的拷贝工作,以及内核缓冲区到磁盘缓冲区或内核的 soket buffer 到网卡设备的拷贝工作,而内核缓冲区到用户缓冲区之间的拷贝工作仍然由CPU负责。
操作系统文件I/O
标准(缓存)IO和直接IO的区别在于是否经过内核页缓存 page cache。
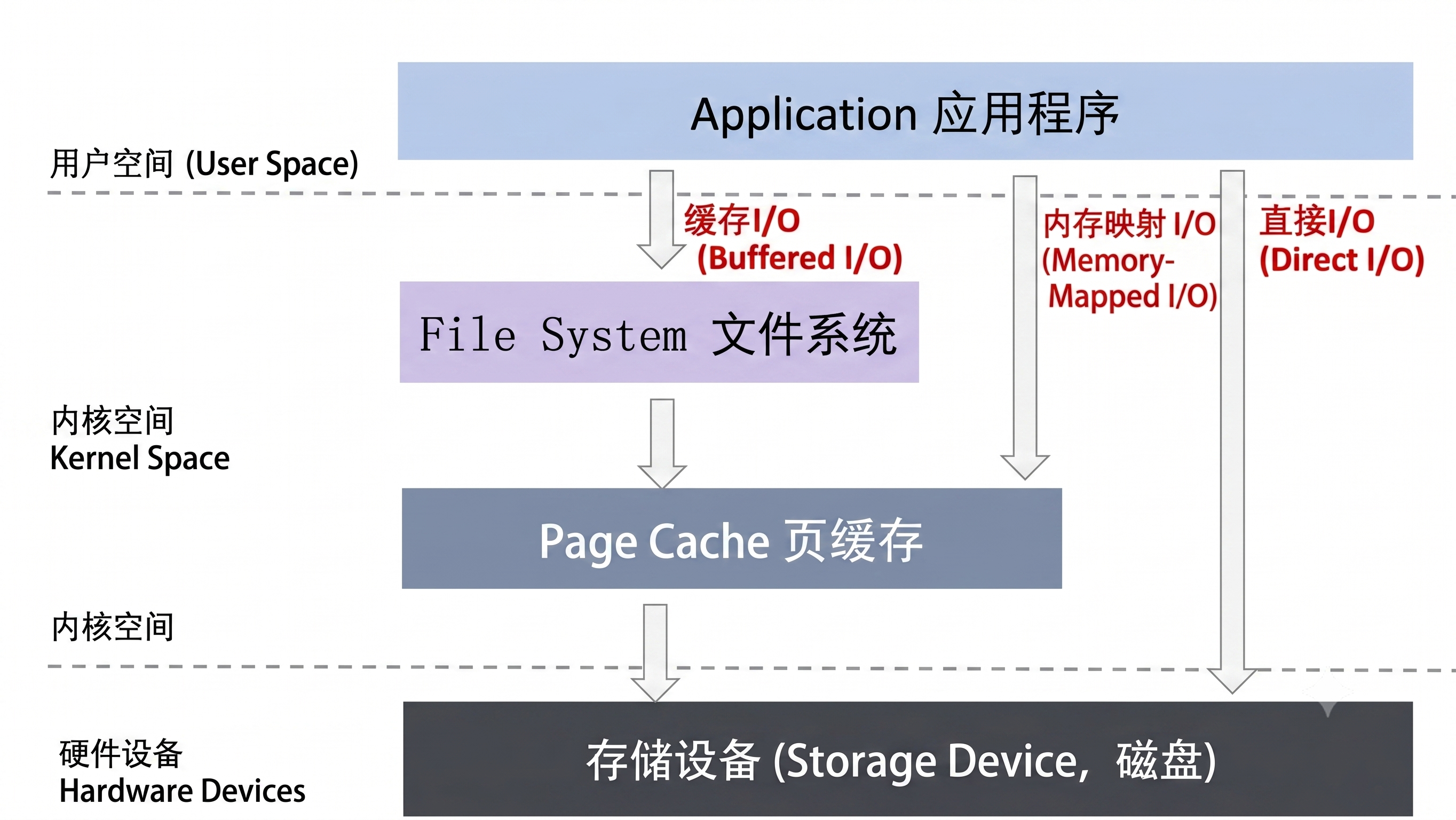
缓存I/O
缓存I/O又被称作标准I/O,大多数文件系统的默认I/O操作都是缓存I/O。在Linux的缓存I/O机制中,数据先从磁盘复制到内核空间的缓冲区,然后从内核空间缓冲区复制到应用程序的地址空间。
读操作:操作系统检查内核的缓冲区有没有需要的数据,如果已经缓存了,那么就直接从缓存中返回;否则从磁盘中读取,然后缓存在操作系统的缓存中,最后再复制到用户空间缓冲中。
写操作:将数据从用户空间复制到内核空间的缓存中。这时对用户程序来说写操作就已经完成,至于什么时候再写到磁盘中由操作系统决定,除非显示地调用了sync同步命令。
缓存IO的优点:简单、通用,并且适合大多数普通程序。应用程序只需要正常调用 read/write,内核会通过 page cache 自动缓存热点数据、做预读、合并写入和延迟回写。对于重复读取、小文件访问、顺序读写、一般业务程序来说,缓存 I/O 往往性能更好,因为很多读请求可以直接从内存命中,很多写请求也可以先写入内存后再由内核异步刷盘,减少应用等待时间。
缓存IO的缺点:应用对数据何时真正落盘的控制较弱。write() 返回通常只说明数据进入了 page cache,不代表已经写入磁盘,真正持久化还需要 fsync()、fdatasync() 或内核后台回写。同时,缓存 I/O 会多一次用户缓冲区和 page cache 之间的数据拷贝,占用额外 CPU 和内存。如果应用本身已经有缓存机制,比如数据库的 buffer pool,那么再经过 page cache 就可能形成双重缓存,浪费内存,也会让应用难以精确控制缓存淘汰和刷盘时机。
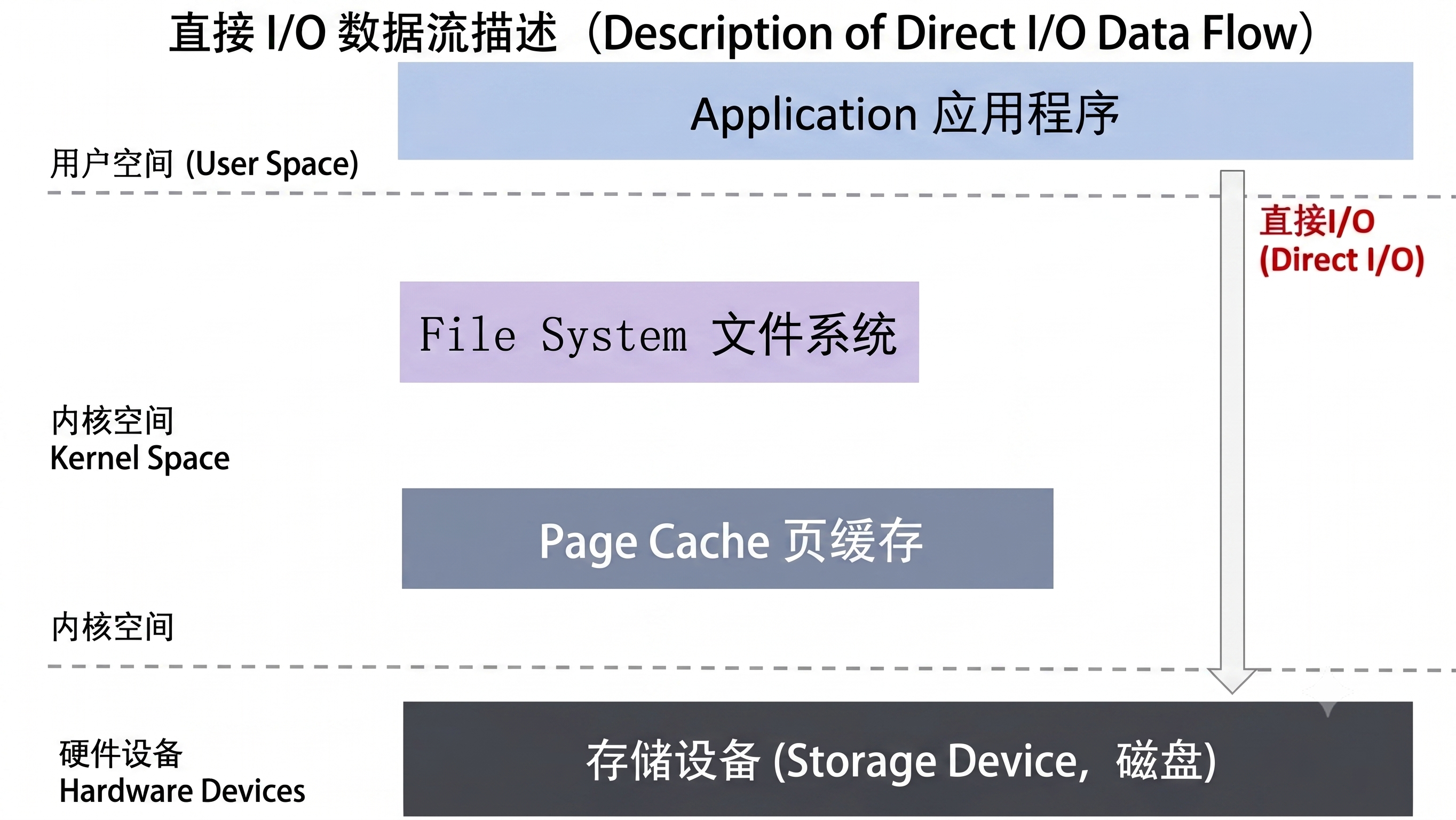
直接I/O
顾名思义,直接IO就是应用程序直接访问磁盘数据,而不经过内核缓冲区,也就是绕过内核缓冲区,自己管理I/O缓冲区,这样做的目的是减少一次从内核缓冲区到用户程序缓冲的数据复制。
引入内核缓冲区的目的在于提高磁盘文件的访问性能,因为内存缓冲区的访问速度比磁盘更快,当进程需要读取磁盘文件时,如果文件内容已经在内核缓冲区中,那么就不需要再次访问磁盘。而当进程需要向文件写入数据时,实际上只是写到了内核缓冲区便告诉进程已经写成功,而真正写入磁盘是通过一定的策略进行延时的。
然对于一些较复杂的应用,可以避免数据库、虚拟机监控器这类系统出现双重缓存。比如数据库服务器,他们为了充分提高性能,希望绕过内核缓冲区,由自己在用户态空间时间并管理IO缓冲区,包括缓存机制和写延迟机制等,以支持独特的查询机制,比如数据库可以根据加合理的策略来提高查询缓存命中率。另一方面,绕过内核缓冲区也可以减少系统内存的开销,因为内核缓冲区本身就在使用系统内存。
直接 I/O 的缺点是使用成本更高。它通常要求用户缓冲区地址、I/O 长度、文件偏移满足对齐要求,否则可能失败或退化。它也失去了内核 page cache 带来的自动优化,小 I/O、重复读、普通文件访问可能反而更慢。如果访问的数据不在应用程序缓存中,那么每次数据都会直接从磁盘加载,这种直接加载会非常缓慢。通常直接IO与异步IO结合使用,会得到比较好的性能。
操作系统I/O模型
Linux系统有五种I/O模型:阻塞I/O、非阻塞I/O、I/O多路复用、同步I/O、异步I/O。
一开始我错误的认为,非阻塞 I/O 就是异步 I/O ,阻塞 I/O 就是同步 I/O 。后来才发现,原来并不是这样的。IO 的分类有两个维度,一个是按调用方式分为:同步 和 异步;另一个是按等待方式分为:阻塞 和 非阻塞。
简单说 阻塞/非阻塞 是指 函数调用时的返回行为 ,而 同步/异步 是指 I/O的完成通知 。 而 I/O多路复用 则是一种特殊的技术,是提升效率的一种机制,它允许单个线程同时管理多个 I/O 操作。通过使用 select、poll 或 epoll 等系统调用,应用程序可以在多个文件描述符上等待事件的发生,从而实现高效的 I/O 处理。I/O多路复用通常与非阻塞 I/O 结合使用,以提高性能和响应能力。
| 模型 | 应用行为 | 等待位置 | 优缺点 |
|---|---|---|---|
| 同步 I/O | 等待完成 | 应用自己阻塞 | 简单,但效率低 |
| 异步 I/O | 发起请求立刻返回,完成后通知 | 内核异步完成 | 最理想,但实现复杂 |
| 阻塞 I/O | 调用阻塞直到数据就绪 | 应用阻塞 | 编程简单,但浪费等待时间 |
| 非阻塞 I/O | 数据没好立即返回,需要轮询 | 应用层轮询 | 避免阻塞,但效率差 |
| I/O 多路复用 | 统一等待多个 I/O 就绪 | 内核等待,应用一次醒来处理 | 高效,常用于高并发服务器 |
阻塞I/O
阻塞 I/O 的特点是调用后如果条件不满足,线程会被内核挂起。以 socket 的 read() 为例,如果接收缓冲区里没有数据,应用调用 read() 后会陷入内核,内核发现暂时无数据,就把这个线程放到等待队列中并调度其他线程运行。等网卡收到数据、协议栈把数据放入 socket 接收缓冲区后,内核再唤醒这个线程,随后 read() 把数据从内核缓冲区复制到用户缓冲区并返回。它的优点是编程模型简单,代码像顺序执行一样;缺点是一个线程在等待一个 I/O 时无法处理其他连接,所以如果要同时处理大量连接,单纯阻塞 I/O 往往需要大量线程或进程,调度和栈内存开销会很高。
示例如下,父进程从管道读取数据,子进程 3 秒后才写入,所以父进程的 read() 会一直停在内核里,直到管道中有数据可读:
1 | |
当调用 read() 时,线程陷入阻塞,无法处理其他业务,等待读入数据,如果内核发现当前没有数据可读,就会把调用线程挂起。它的优点是代码顺序清晰,编程简单;缺点是一个线程在等待 I/O 时无法处理其他事情,如果大量连接都采用这种方式,通常需要大量线程或进程来支撑并发。
非阻塞I/O
非阻塞 I/O 的特点是调用后不等待。如果文件描述符被设置为非阻塞,例如 socket 设置了 O_NONBLOCK,那么应用调用 read() 时,如果内核发现暂时没有数据,不会把线程挂起,而是立即返回错误码,常见是 EAGAIN 或 EWOULDBLOCK。应用可以稍后再试。它的优点是线程不会因为某个 I/O 卡住,可以继续处理别的逻辑;缺点是如果应用反复循环调用 read() 探测数据是否到来,就会形成忙等,占用 CPU。所以非阻塞 I/O 通常不会单独使用,而是配合 I/O 多路复用。
示例如下,父进程把管道读端设置为 O_NONBLOCK,此时如果没有数据,read() 不会睡眠,而是立即返回 EAGAIN:
1 | |
系统调用不会因为暂时没有数据而把线程挂起。应用程序可以拿到 EAGAIN 后继续执行其他逻辑,之后再尝试读取。它适合事件驱动程序,但如果应用不断循环调用 read() 查询是否有数据,就会形成忙等,浪费 CPU。因此非阻塞 I/O 通常不会单独使用,通常会和 select、poll、epoll 这类 I/O 多路复用机制配合使用。
同步I/O
同步 I/O 的关键是应用是否需要亲自发起并完成数据读写过程。从 POSIX 语义看,只要真正的数据传输仍然是在应用调用 read/write 时完成,通常都属于同步 I/O。阻塞 I/O 是同步 I/O,因为线程等待数据到来,并在 read() 返回前完成数据拷贝。非阻塞 I/O 也是同步 I/O,因为即使它没数据时立即返回,等数据可读后,应用仍然要再次调用 read(),由这个调用完成从内核缓冲区到用户缓冲区的数据拷贝。I/O 多路复用也通常属于同步 I/O,因为 epoll_wait() 只通知“可读/可写”,应用还要自己调用 read/write 完成 I/O 操作。
同步I/O示例如下,这里使用普通文件的 pread(),它的特点是调用发起后,内核会在这个调用过程中完成读取,并在返回前把数据复制到用户缓冲区:
1 | |
应用调用 pread(),真正的数据读取动作在这个系统调用过程中完成,调用返回后用户缓冲区里已经有结果。需要注意,同步 I/O 和阻塞 I/O不是完全等价的概念。阻塞 I/O、非阻塞 I/O、I/O 多路复用通常都属于同步 I/O,因为它们最终都需要应用亲自调用 read() 或 write() 完成数据传输。同步 I/O强调的是“应用发起的这个读写调用负责把 I/O 做完”,而不是“这个调用一定会长时间阻塞”。