
数据库头歌作业
数据库系统概述
数据管理技术的发展
-
1、下面列出的数据库管理技术发展的三个阶段中,没有专门的软件对数据进行管理的是(A)。
A、人工管理阶段
B、文件系统阶段
C、数据库阶段
-
2、下面关于数据库系统叙述正确的是(B)。
A、数据库系统避免了一切冗余
B、数据库系统减少了数据冗余
C、数据库系统文件能管理更多的数据
D、数据库系统中数据的一致性是指数据类型的一致
-
3、下列叙述中,错误的是(C)。
A、数据库技术的根本目标是要解决数据共享的问题
B、数据库设计是指设计一个能满足用户要求,性能良好的数据库
C、数据库系统中,数据的物理结构必须与逻辑结构一致
D、数据库系统是一个独立的系统,但是需要操作系统的支持
数据库系统概论
-
1、数据库系统是采用了数据库技术的计算机系统,数据库系统由数据库、数据库管理系统、应用系统和(C)。
A、系统分析员
B、程序员
C、数据库管理员
D、操作员
-
2、数据库(DB),数据库系统(DBS)和数据库管理系统(DBMS)之间的关系是(A)。
A、DBS包括DB和DBMS
B、DBMS包括DB和DBS
C、DB包括DBS和DBMS
D、DBS就是DB,也就是DBMS
-
3、下面四项中,不属于数据库系统特点的是(C)。
A、数据共享
B、数据完整性
C、数据冗余度高
D、数据独立性高
-
4、下面(D)不是 DBA 数据库管理员的职责。
A、完整性约束说明
B、定义数据库模式
C、数据库安全
D、数据库管理系统设计
数据库系统的结构
-
1、描述数据库全体数据的全局逻辑结构和特征的是()。
A、概念模式
B、内模式
C、外模式
-
2、要保证数据库的数据独立性,需要修改的是()。
A、概念模式与外模式
B、概念模式与内模式
C、三级模式之间的两层映射
D、三层模式
-
3、用户或应用程序看到的那部分局部逻辑结构和特征的描述是()模式。
A、概念
B、物理模式
C、子模式
D、内模式
-
4、数据库三级结构从内到外的3个层次依次为()。
A、外模式、概念模式、内模式
B、内模式、概念模式、外模式
C、概念模式、外模式、内模式
D、内模式、外模式、概念模式
关系模型
关系模型的基本概念
-
1、数据库技术的奠基人之一 E.F.Codd 从 1970 年起发表过多篇论文,主要论述的是()。
A、层次数据模型
B、网状数据模型
C、关系数据模型
D、面向对象数据模型
-
2、在关系数据库设计中用()来表示实体及实体之间的联系。
A、树结构
B、封装结构
C、二维表结构
D、图结构
-
3、下面的选项不是关系数据库基本特征的是()。
A、不同的列应有不同的数据类型
B、不同的列应有不同的列名
C、与行的次序无关
D、与列的次序无关
-
4、关系模型中,一个码是()。
A、可以由多个任意属性组成
B、至多由一个属性组成
C、 由一个或多个属性组成,其值能够惟一标识关系中一个元组
D、 以上都不是
-
5、下列叙述中,哪一条是不正确的()。
A、一个二维表就是一个关系,二维表的名就是关系的名
B、关系中的列称为属性,属性的个数称为关系的元或度
C、关系中的行称为元组,对关系的描述称为关系模式
D、属性的聚会范围称为值域,元组中的一个属性值称为分量
关系代数
-
1、关系代数运算是以()为基础的运算 。
A、关系运算
B、谓词演算
C、集合运算
D、代数运算
-
2、有两个关系 R 和 S,分别包含15个和10个元组,那么在R∪S、R-S、R∩S,中不可能出现的元组数目情况是()。
A、15,5,10
B、18,7,7
C、21,11,4
D、25,15,0
-
3、参加差运算的两个关系()。
A、属性个数可以不相同
B、属性个数必须相同
C、一个关系包含另一个关系的属性
D、属性名必须相同
-
4、若D1={a1,a2,a3},D2={1,2,3},则 D1×D2 集合中共有元组()个。
A、6
B、8
C、9
D、12
-
5、设有关系 R,S 和 T 如下图所示。关系 T 是由关系 R 和 S 经过哪种操作得到的()。
A、交
B、并
C、差
D、笛卡尔积
扩展关系代数
-
1、关系代数中的连接操作是由()操作组合而成 。
A、选择和投影
B、选择和笛卡尔积
C、投影、选择、笛卡尔积
D、投影和笛卡尔积
-
2、从一个数据库文件中取出满足某个条件的所有记录形成一个新的数据库文件的操作是()操作 。
A、投影
B、连接
C、选择
D、复制
-
3、一般情况下,当对关系 R 和 S 进行自然连接时,要求 R 和 S 含有一个或者多个共有的()。
A、记录
B、行
C、属性
D、元组
-
4、取出关系中的某些列,并消去重复元组的关系代数运算称为()。
A、取列运算
B、投影运算
C、连接运算
D、选择运算
-
5、在学生表中要查找所有年龄大于30岁姓王的男同学,应该采用的关系运算是()。
A、选择
B、投影
C、连接
D、自然连接
关系演算
-
1、设关系 R 和关系 S 具有相同的属性个数,且相应的属性取自同一个域,则{t∣t∈R⋀¬t∈S} t 是元组变量,其结果关系是()。
A、R∪S
B、R-S
C、R∩S
D、R-(R-S)
-
2、在关系演算中,元组变量的变化范围是()。
A、某一命名的关系
B、数据库中的所有关系
C、某一个域
D、数据库中的所有域
-
3、关系演算的基础是()。
A、形式逻辑中的逻辑演算
B、形式逻辑中的关系演算
C、数理逻辑中的谓词演算
D、数理逻辑中的形式演算
关系系统
-
1、数据库系统的数据独立性体现在()。
A、不会因为数据的变化而影响到应用程序
B、不会因为数据存储结构与数据逻辑结构的变化而影响应用程序
C、不会因为存储策略的变化而影响存储结构
D、不会因为某些存储结构的变化而影响其他的存储结构
-
2、下列关于关系的叙述中,正确的是()。
A、关系是一个由行与列组成的、能够表达数据及数据之间联系的二维表B、表中某一列的数据类型既可以是字符串,也可以是数字
C、表种某一列的值可以取空值null,所谓空值是指安全可靠或零
D、表中必须有一列作为主关键字,用来唯一标识一行
关系数据库逻辑设计问题
相关知识
关系数据库逻辑设计问题
设计任何一种数据库应用系统,不论是层次的、 网状的还是关系的,都会遇到如何构造合适的数据模式即逻辑结构的问题。由于关系模型有严格的数学理论基础,并且可以向别的数据模型转换,因此,人们就以关系模型为背最来讨论这个问题,形成了数据库逻辑设计的一个有力工具-关系数据库的规范化理论。规范化理论虽然是以关系模型为背景,但是它对于一般的数据库逻辑设计同样具有理论上的意义。
关系模型的形式化定义:
一个关系模式应当是一个如下所示五元组。 R(U,D,DOM,F) 在上述公式中,关系名 R 是符号化的元组语义;U为一组属性;D为属性组U中的属性所来自的域;DOM为属性到域的映射;F为属性组U上的一组数据依赖; 由于 D、DOM 与模式设计关系不大,因此在本实训中把关系模式看作一个三元组: R<U,F> 当且仅当 U 上的一个关系 r 满足 F 时,r 称为关系模式R<U,F>的一个关系。 作为一个二维表,关系要符合一个最基本的条件:每一个分量必须是不可分的数据项。满足了这个条件的关系模式就属于第一范式(INF)。
在模式设计中,假设已知一个模式SΦ, 它仅由单个关系模式组成,问题是要设计一个模式SD,它与SΦ等价,但在某些指定的方面更好一些。这里通过一个例子来说明一个不好的模式会有些什么问题,分析它们产生的原因,并从中找出设计一个好的关系模式的办法。 在举例之前,先非形式地讨论一下数据依赖的概念。 数据依赖是一个关系内部属性与属性之间的一种约束关系。 这种约束关系是通过属性间值的相等与否体现出来的数据问相关联系。它是现实世界属性间相互联系的抽象,是数据内在的性质,是语义的体现。人们已经提出了许多种类型的数据依赖,其中最重要的是函数依赖( FunctionalDependency, FD)和多值依赖( Multi-Valued Dependency, MVD)。 函数依赖极为普遍地存在于现实生活中。比如描述一个学生的关系,可以有学号(Sno)、姓名(Sname)、 系名(Sdept) 等几个属性。由于一个学号只对应一个学生,一个学生只在一个系学习。因而当“学号”值确定之后,学生的姓名及所在系的值也就被唯一地确定了。属性间的这种依赖关系类似于数学中的函数y=f(x),自变量x确定之后,相应的函数值y也就唯一地确定了。 类似的有Sname=f(Sno),Sdept=f(Sno), 即 Sno 函数决定 Sname,或者说 Sname 和 Sdept 函数依赖于 Sno,记作 Sno→Sname, Sno→Sdept。
【示例】:建立一个描述学校教务的数据库,该数据库沙及的对象包括学生的学号(Sno)、所在系(Sdept)、系主任姓名(Mname)、课程号(Cno)和成绩(Grade)。假设用一个单一的关系模式Student来表示,则该关系模式的属性集合为: U={Sno,Sdept,Mname,Cno,Grade}
现实世界的已知事实(语义)告诉我们: ①一个系有若干学生,但一个学生只属于一个系; ②一个系只有一名(正职)负责人; ③一个学生可以选修多门课程,每门课程有若干学生选修; ④每个学生学习每一门课程有一个成绩。
于是得到属性组U上的一组函数依赖F (如下图所示)。
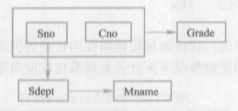
F={Sno→Sdept,Sdept→Mname,(Sno,Cno)→Grade) 如果只考虑函数依赖这一种 数据依赖,可以得到一个描述学生的关系模式Student<U,F>。下表是某一时刻关系模式Student的一个实例,即数据表。
| Sno | Sdept | Mname | Cno | Grade |
|---|---|---|---|---|
| S1 | 计算机系 | 张明 | C1 | 95 |
| S2 | 计算机系 | 张明 | C1 | 94 |
| … | … | … | … | … |
但是,这个关系模式存在以下问题; (1)数据冗余 比如,每一个系的系主任姓名重复出现,重复次数与该系所有学生的所有课程成绩出现次数相同,如上表 所示。这将浪费大量的存储空间。 (2) 更新异常 由于数据冗余,当更新数据库中的数据时,系统要付出很大的代价来维护数据库的完整性,否则会面临数据不一致的危险。 比如,某系更换系主任后,必须修改与该系学生有关的每一个元组。 (3)插入异常 如果一个系刚成立,尚无学生,则无法把这个系及其系主任的信息存入数据库。 (4)删除异常 如果某个系的学生全部毕业了,则在删除该系学生信息的同时,这个系及其系主任的信息也丢掉了。 鉴于存在以上种种问题,可以得出这样的结论: Student关系模式不是一个好的模式。一个好的模式应当不会发生插入异常、 删除异常和更新异常, 数据冗余应尽可 能少。 为什么会发生这些问题呢? 这是因为这个模式中的函数依赖存在某些不好的性质。这正是本实训要讨论的问题。假如把这个单一的模式改造一下,分成三个关系模式: S(Sno,Sdept,Sno→Sdep): SC(Sno,Cno,Grade,(Sno,Cno)→Grade): DEPT(Sdept,Mname,Sdept→Mname) 这三个模式都不会发生插入异常、删除异常的问题,数据的冗余也得到了控制。
题目
-
1、对于关系而言,每一个分量必须是不可分的数据项。满足了这个条件的关系模式就属于第二范式(INF)。
A、错误
B、正确
-
2、数据依赖是一个关系内部属性与属性之间的一种约束关系。
A、正确
B、错误
规范化
相关知识
本实训将讨论一个关系属性间不同的依赖情况,讨论如何根据属性间依赖情况来判定关系是否具有某些不合适的性质,通常按属性间依赖情况来区分关系规范化程度为第一范式、第二范式、第三范式和第四范式等;然后 直观地描述如何将具有不合适性质的关系转换为更合适的形式。 上一个实训中关系模式Student<U,F>中有Sno→Sdept 成立,也就是说在任何时刻 Student 的关系实例(即Student 数据表)中,不可能存在两个元组在Sno上的值相等,而在Sdept上的值不等。因此,下表的Student表是错误的。因为表中有两个元组在Sno上都等于SI, 而Sdept.上一个为计算机系,一个为自动化系。
函数依赖
设 R(U) 是属性集 U 上的关系模式,X,Y 是 U 的子集。若对于 R(U) 的任意一个可能的关系 r,r 中不可能存在两个元组在 X 上的属性值相等,而在 Y 上的属性值不等,则称X函数确定Y或Y函数依赖于X,记作X→Y。 函数依赖和别的数据依赖样是语义范畴的概念,只能根据语义来确定一个函数依赖。例如,姓名一年龄这个函数依赖只有在该部门没有同名人的条件下成立。如果允许有同名人,则年龄就不再函数依赖于姓名了。 设计者也可以对现实世界作强制性规定,例如规定不允许同名人出现,因而使姓名一年龄函数依赖成立。这样当插入某个元组时这个元组上的属性值必须满足规定的函数依赖,若发现有同名人存在,则拒绝插入该元组。
注意,函数依赖不是指关系模式R的某个或某些关系满足的约束条件,而是指 R 的一切关系均要满足的约束条件。
在 R(U) 中,如果 X→Y, 并且对于 X 的任何一个真子集X’,都有X’↛Y,则称 Y 对 X 完全函数依赖,记作 X⟶FY
若X→Y,但 Y 不完全函数依赖于 X,则称 Y 对 X 部分函数依赖( partial functionaldependency),记作 X⟶PY
码
使用函数依赖的方式来定义码。 设 K 为 R<U,F> 中的属性或属性组合,若K⟶FU,则 K 为 R 的候选码(candidatekey)。 注意 U 是完全函数依赖于 K,而不是部分函数依赖于 K。如果 U 部分函数依赖于 K,即K⟶PU,则 K 称为超码(Surpkey)。候选码是最小的超码,即 K 的任意一个真子集都不是候选码。 若候选码多于一个,则选定其中的一个为主码(primary key)。 包含在任何一个候选码中的属性称为主属性(primeattribute);不包含在任何候选码中的属性称为非主属性(nonprime attribute)或非码属性(non-key attribute)。最简单的情况,单个属性是码;最极端的情况,整个属性组是码,称为全码(all-key)。
范式
关系数据库中的关系是要满足一定 要求的,满足不同程度 要求的为不同范式。 满足最低要求的叫第一范式, 简称 1NF;在第一范式中满足进一步要求的为第二范式,其余以此类推。 现在我们常把范式这个概念理解成符合某一种级别的关系模式的集合,即R为第几范式就可以写成RE∈xNF 。对于各种范式之间的关系有 3NF⊂2NF⊂1NF 成立。 一个低一级范式的关系模式通过模式分解可以转换为若干个高一级范式的关系模式的集合,这种过程就叫规范化。
- 2NF
若R∈INF,且每个非主属性完全函数依赖于任何一个候选码,则RE∈2NF。
- 3NF
设关系模式 R<U,F>∈1NF,若 R 中不存在这样的码 X,属性组 Y 及非主属性Z (Y\\⊆Z)使得X→Y, Y→Z成立,Y↛X,则称R<U, F>∈3NF。 因此可以证明,若R∈3NF,则每一个非主属性既不传递依赖于码,也不部分依赖于码。也就是说,可以证明如果 R 属于 3NF,则必有 R 属于 2NF。
实训
-
1、一个低一级范式的关系模式通过模式分解可以转换为若干个高一级范式的关系模式的集合,这种过程就叫规范化
A、正确
B、错误
-
2、设 K 为R<U,F>中的属性或属性组合,若
K⟶FU,则 K 为 R 的主码。A、正确
B、错误
数据库设计
数据库设计的步骤与方法
-
1、数据库设计可划分为六个阶段,每个阶段都有自己的设计内容,“为哪些关系在哪些属性上建立什么样的索引”这一设计内容属于()设计阶段。
A、概念设计
B、逻辑设计
C、物理设计
D、全局设计
-
2、下列关于数据库运行和维护的叙述中,正确的是()。
A、只要数据库正式投入运行,就标志着数据库设计工作的结束
B、数据库的维护工作就是维护数据库系统的正常运行
C、数据库的维护工作就是发现错误,修改错误
D、数据库正式投入运行标志着数据库运行与维护工作的开始
需求分析
-
1、数据库需求分析时,数据字典的含义是()。
A、数据库中所涉及的属性和文件的名称的集合
B、数据库所涉及到字母、字符及汉字的集合
C、数据库中所有数据的集合
D、数据库中所涉及的数据流、数据项和文件等描述的集合
-
2、下列不属于需求分析阶段工作的是()。
A、分析用户活动
B、建立 E-R 图
C、需求分析
D、建立数据流图
-
3、在需求分析阶段设计数据流程图通常采用()方法。
A、面向对象
B、回溯
C、自底向上
D、自顶向下
-
4、数据流程图是用于数据库设计中()阶段的工具。
A、概要设计
B、可行性分析
C、程序编码
D、需求分析
概念结构设计
-
1、概念结构设计是整个数据库设计的关键,它通过对用户需求进行综合、归纳与抽象,形成一个独立于具体的 DBMS 的()。
A、数据模型
B、概念模型
C、层次模型
D、关系模型
-
2、数据库设计的概念设计阶段,表示概念结构的常用方法和描述工具是()。
A、层次分析法和层次结构图
B、数据流程分析法和数据流程图
C、实体-联系方法
D、结构分析法和模块结构图
-
3、当局部 E-R 图合并称全局 E-R 图时可能出现冲突,不属于合并冲突的是()。
A、属性冲突
B、语法冲突
C、结构冲突
D、命名冲突
-
4、下列不属于概念结构设计时常的数据抽象方法是()。
A、合并
B、聚集
C、概括
D、分类
逻辑结构设计
题目
-
1、如何构造出一个合适的数据逻辑结构是()主要解决的问题。
A、关系数据库优化
B、数据字典
C、关系数据库规范化理论
D、关系数据库查询
-
2、在数据库设计中,将 E-R 图转换为关系数据模型的过程属于()阶段。
A、需求分析
B、逻辑结构设计
C、概念结构设计
D、物理结构设计
-
3、关系数据库的规范化理论主要解决的问题是()。
A、如何构造合适的逻辑结构以减少冗余和操作异常
B、如何构造合适的物理结构以提高数据库运行的效率
C、如何构造合适的应用程序界面以方便用户使用数据库
D、如何控制操作权限以杜绝数据库的非法访问
-
4、子模式 DDL 是用来描述()。
A、数据库的总体逻辑结构
B、数据库的局部逻辑结构
C、数据库的物理存储结构
D、数据库的概念结构
物理结构设计
-
1、数据库设计中,确定数据库存储结构,即确定关系、索引、聚簇、日志、备份等数据的存储安排和存储结构,这是数据库设计的()阶段。
A、需求分析
B、逻辑设计
C、概念设计
D、物理设计
-
2、下列不属于数据库物理设计阶段应该考虑的问题是()。
A、存取方法的选择
B、索引与入口设计
C、与安全性、完整性、一致性有关的问题
D、用户子模式设计
数据库概念结构、逻辑结构、物理结构设计
概念结构设计
-
1、概念结构设计是整个数据库设计的关键,它通过对用户需求进行综合、归纳与抽象,形成一个独立于具体的 DBMS 的()。
A、数据模型
B、概念模型
C、层次模型
D、关系模型
-
2、数据库设计的概念设计阶段,表示概念结构的常用方法和描述工具是()。
A、层次分析法和层次结构图
B、数据流程分析法和数据流程图
C、实体-联系方法
D、结构分析法和模块结构图
-
3、当局部 E-R 图合并称全局 E-R 图时可能出现冲突,不属于合并冲突的是()。
A、属性冲突
B、语法冲突
C、结构冲突
D、命名冲突
-
4、下列不属于概念结构设计时常的数据抽象方法是()。
A、合并
B、聚集
C、概括
D、分类
逻辑结构设计
-
1、如何构造出一个合适的数据逻辑结构是()主要解决的问题。
A、关系数据库优化
B、数据字典
C、关系数据库规范化理论
D、关系数据库查询
-
2、在数据库设计中,将 E-R 图转换为关系数据模型的过程属于()阶段。
A、需求分析
B、逻辑结构设计
C、概念结构设计
D、物理结构设计
-
3、关系数据库的规范化理论主要解决的问题是()。
A、如何构造合适的逻辑结构以减少冗余和操作异常
B、如何构造合适的物理结构以提高数据库运行的效率
C、如何构造合适的应用程序界面以方便用户使用数据库
D、如何控制操作权限以杜绝数据库的非法访问
-
4、子模式 DDL 是用来描述()。
A、数据库的总体逻辑结构
B、数据库的局部逻辑结构
C、数据库的物理存储结构
D、数据库的概念结构
物理结构设计
-
1、数据库设计中,确定数据库存储结构,即确定关系、索引、聚簇、日志、备份等数据的存储安排和存储结构,这是数据库设计的()阶段。
A、需求分析
B、逻辑设计
C、概念设计
D、物理设计
-
2、下列不属于数据库物理设计阶段应该考虑的问题是()。
A、存取方法的选择
B、索引与入口设计
C、与安全性、完整性、一致性有关的问题
D、用户子模式设计
数据库的实施和维护
-
1、数据库的维护工作包括以下哪些内容?(多选)
A、数据库性能的监督、分析和改造
B、数据库的安全性、完整性控制
C、数据库的重组织与重构造
D、数据库的转储和恢复
-
2、以下属于数据库实施阶段重要的工作的是?(多选)
A、数据的载入
B、备份数据库
C、应用程序的编码和调试
关系数据库系统的查询处理
-
1、以下 mysql 查询处理过程正确的是?
A、查询预处理、查询解析、查询缓存、查询优化、查询执行。
B、查询缓存、查询预处理、查询解析、查询优化、查询执行。
C、查询缓存、查询解析、查询预处理、查询优化、查询执行。
D、查询缓存、查询优化、查询预处理、查询解析、查询执行。
-
2、检查查询语句中的表名、列名是否存在,属于查询处理的哪个步骤?
A、查询解析
B、查询预处理
C、查询执行
D、查询缓存



